As a proponent of distributed tracing, I felt the pain of support propagation between services of different technologies. There are several formats for passing tracing information between services to support tracing propagation, and each of them are considered a “standard”. To remedy this, I wrote @oracle/trace-propagation, a node library to include all known formats in a request, thus sparing engineers the requirement of discovering and applying them.
How Does Tracing Propagation Work?
When tracing is distributed, it means functional behavior extending beyond one thread is traced, and that information is stitched together for observation. It is incredibly useful in understanding a complex system of services, and seeing how the integration between services supports the functional behavior. Each unit of work by a service is called a span, and the trace is the entire workflow composed of spans.
For a span to link to another span under a single trace, specific metadata must be present to bind them together. Propagation is the inclusion of this metadata so the spans can join under one trace.
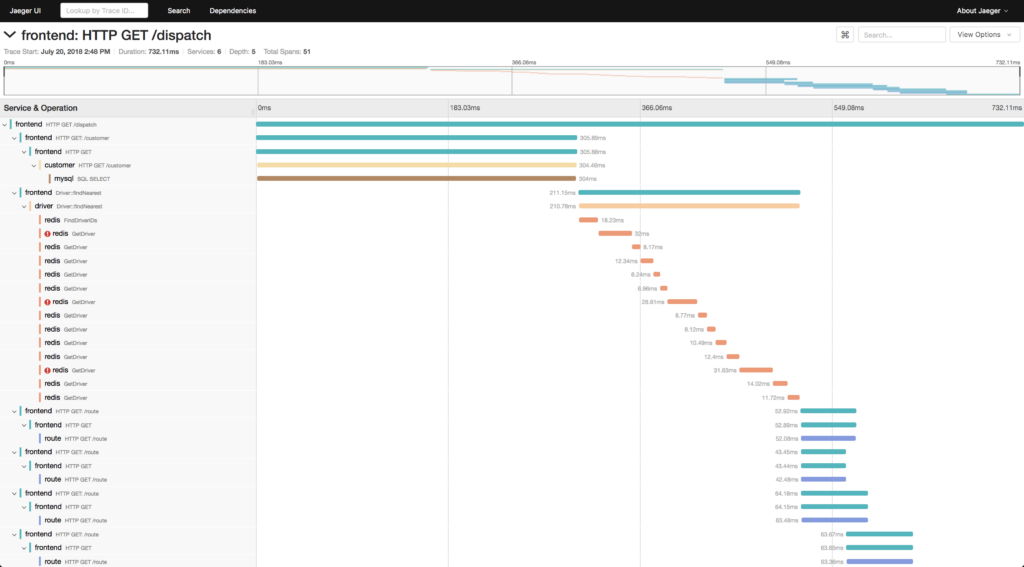
The image above depicts a properly propagated trace across multiple levels of functionality.
Example Use Case
Let’s dive into an example usage. Consider my Node Express server which supports tracing using jaeger-client and opentracing. I also have a Spring Boot Java server using Spring Cloud Sleuth. The default propagation format for Sleuth is Zipkin’s B3 format. However, if I were to use Opentracing’s Spring Jaeger Cloud Starter, then the format would be W3C’s format. And what if the backend I’m calling is written in Python or Go?
Using the @oracle/trace-propagation library, I do not need to know what format is supported by downstream services. I add headers built from this library to my request to cover all formats:
import { constructPropagation } from'@oracle/trace-propagator';
let promise = fetch(url, {
headers: constructPropagation({ traceId, spanId })
});